3.1.3 결측치 평균값으로 대체하기
먼저 결측치를 봐야 한다.
df.isnull()
하지만 아무런 결측치가 없으므로 sum() 까지 사용한다.
하지만 우리가 이 데이터를 요약했을 때,
df.describe()
다음과 같은 결과에서 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI' 와 같이 최솟값이 0이 될 수 없는데 0이 들어가는 항목들이 존재한다.
우선, 인슐린을 가져오는데, 인슐린이 0보다 큰 값과 0보다 작은 값을 시각화 했을 때 Outcome 값과 확연히 구분되는 값들이 존재하기 때문에 예측을 하기 위해 0인 값을 고려해야 한다. 따라서 0 이 들어가는 값을 np.nan 을 사용해 NaN으로 바꿔준다.
df["Insulin_nan"]=df["Insulin"].replace(0,np.nan)
df["Insulin_nan"]
Insulin과 Insulin_nan의 상위 5개 컬럼만 확인해보자.
df["Insulin_nan"]=df["Insulin"].replace(0,np.nan)
df[["Insulin","Insulin_nan"]].head()
Insulin_nan에 isnull().sum() 을 사용해 총 결측치를 확인해보자.
df["Insulin_nan"].isnull().sum()
했을 때 결과가 "374" 가 나오는데, 이는 결측치가 374개 있다는 뜻이다.
mean()을 통해 결측치의 비율도 확인해보자.
df["Insulin_nan"].isnull().mean()
결측치의 비율이 48%나 된다..
결측치를 처리한 데이터와 처리하지 않은 데이터의 평균값이 어떻게 차이가 나는지 확인해보자.
df.groupby(["Outcome"])["Insulin","Insulin_nan"].mean()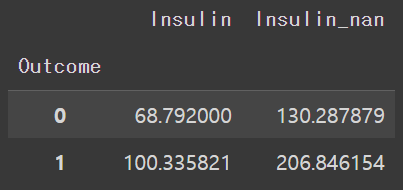
Outcome이 0일 때와 1일 때의 Insulin과 Insulin_nan의 결측치 데이터 모두 차이가 크게 나오는 것을 알 수 있다.
결측치가 너무 많으면 학습을 할 떄 오류가 발생할 확률이 증가한다.
결측치를 그대로 놔둔 채 학습을 진행해보자.
~이하 생략~
remove()를 사용해Insulin 값을 지워서 Insulin_nan 값만 남게 해주자.
feature_names=train.columns.tolist()
feature_names.remove("Pregnancies")
feature_names.remove("Outcome")
feature_names.remove("Insulin")
feature_names

이후 학습을 돌리면..
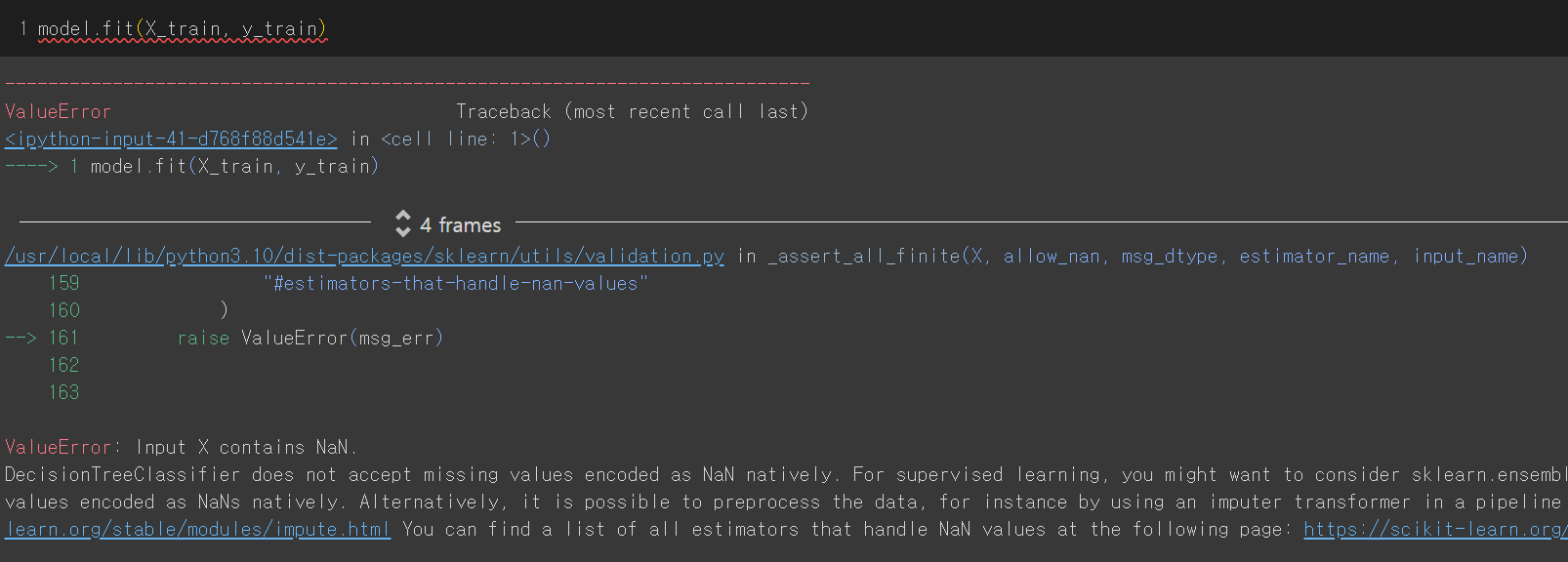
결측치를 포함했기 때문에 value error가 뜬다. 그러므로 결측치를 채워야 한다.
우선 agg() 함수를 통해 Insulin과 Insulin_nan 에서 mean 값과 median값만 따로 보자.
df.groupby(["Outcome"])["Insulin","Insulin_nan"].agg(["mean","median"])

차이가 쫌 많이 나는 것을 알 수 있다.
이제 결측치를 채워보겠다.
Outcome의 값이 0일 경우엔 결측치인 130을, 1일 경우엔 206을 넣어줘 결측치를 없애보자.
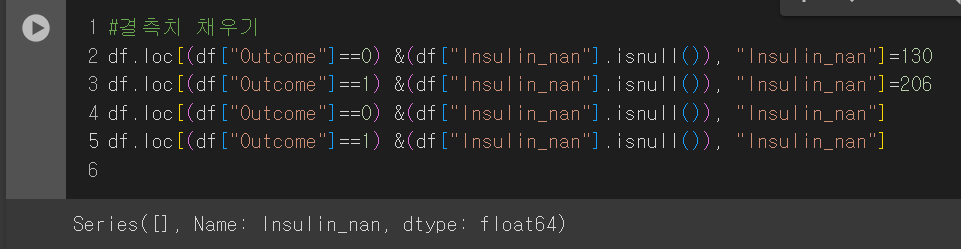
Insulin_nan이 isnull()인 값에 각각의 결측치를 삽입하면 다음과 같이 결측치가 없어짐을 알 수 있다.
이제 다시 학습을 돌려보자.
그리고 feature에서 정확도가 낮았던 Age_low, Age_middle, Age_high는 지워주겠다.
feature_names=train.columns.tolist()
feature_names.remove("Pregnancies")
feature_names.remove("Outcome")
feature_names.remove("Age_low")
feature_names.remove("Age_middle")
feature_names.remove("Age_high")
feature_names.remove("Insulin")
feature_names
계속해서 학습을 돌려보면 fit이 정상적으로 작동하는 것을 볼 수 있다.

이후 DecisionTree를 그려보면,
from sklearn.tree import plot_tree
plt.figure(figsize=(20,20))
tree=plot_tree(model,
feature_names=feature_names,
filled=True,
fontsize=10)

이전과 달리, 결측치를 채운 후 Insulin이 당뇨병 여부에 가장 중요한 역할을 함을 알 수 있다.
중요도를 시각화했을 때도 이전과 달리 인슐린 값이 가장 큰 역할을 함을 알 수 있다.

인슐린 결측치를 평균으로 대체한 값과 실제 정답값과의 차이를 구해보자.
diff_count = abs(y_test - y_predict).sum()
diff_count
값이 24가 나온다. 이는 앞서 나이를 기준으로 한 값에 비해 차이가 확연히 줄어듬을 알 수 있다.
예측 정확도를 비율로도 구해보자.

예측 정확도를 비율로 나타내보니, 다음과 같이 84%가 나왔다. 이는 이전보다 성능이 높아졌음을 알 수 있다.
3.1.4 결측치 중앙값으로 대체하기
이번엔 평균값이 아닌, 중앙값으로 대체했을 때 얼마나 증가하는 지 알아보겠다.

우선, 다시 원본 데이터 돌려 결측치를 만들어주었다.
~이하 생략~
이후 결측치에 중앙값인 102와 169를 넣어주도록 하겠다. 참고로 Outcome이 0인 경우에 102, 1인 경우에 169를 넣어주겠다.
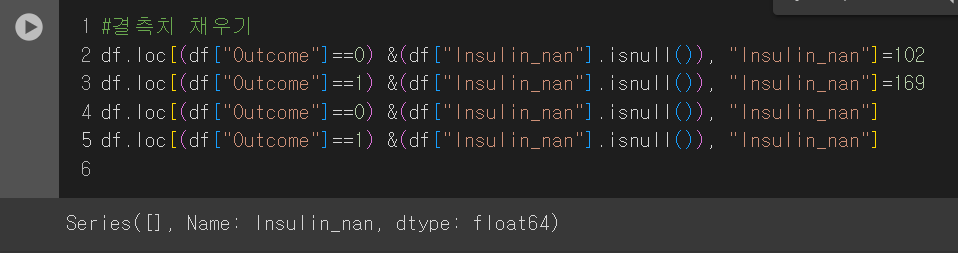
이후 머신러닝을 다시 돌려준다.
~이하 생략~
이후 DecisionTree 를 만들어주면,

다음과 같이 의사결정나무가 만들어지며, 인슐린이 가장 중요함을 알 수 있다. 또한 나무가 아래로 깊게 내려옴을 알 수 있다. 또한 샘플이 적어지는데, 이는 오버피팅을 방지하기 위함이다.
이후 다시 정확도를 추출하면,

강의와 달리, 오차 범위가 줄어들지 않았으며, 정확도도 차이가 없다., 아무리 강의와 똑같을 순 없어도 평균값으로 대체했을 때랑 너무 똑같기 때문에 이 경우는 문제를 찾아봐야 할 것 같다.